Do VLMs Need Vision Transformers? Evaluating State Space Models as Vision Encoders
Shang-Jui Ray Kuo and Paola Cascante-Bonilla
. Featured on Hugging Face Daily Papers , 2026
Under review
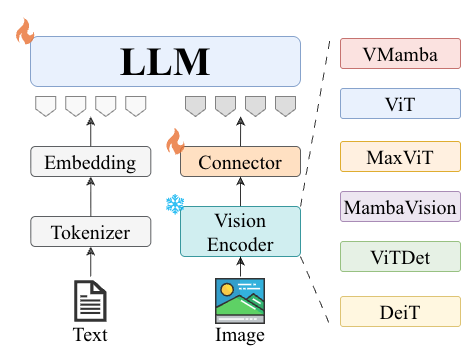
We conduct a controlled study comparing Transformer, SSM, and hybrid vision backbones as frozen encoders in a LLaVA-style VLM pipeline. Under matched pretraining conditions, SSM backbones (VMamba) provide substantially stronger spatial grounding while remaining competitive on open-ended VQA, and can match or outperform much larger ViT-based encoders on localization benchmarks. We further show that localization failures can be stabilized with simple interface adjustments.